Good news! Kyutai STT, the speech-to-text model powering Unmute, is now open-source! This is the first part of the Unmute release.
Kyutai STT is a streaming speech-to-text model architecture, providing an unmatched trade-off between latency and accuracy, perfect for interactive applications. Its support for batching allows for processing hundreds of concurrent conversations on a single GPU. We release two models:
kyutai/stt-1b-en_fr, a low-latency model that understands English and French, and has a built-in semantic voice activity detector.kyutai/stt-2.6b-en, a larger English-only model optimized to be as accurate as possible.
Check out the project page for more details and to get started with the model.
The numbers
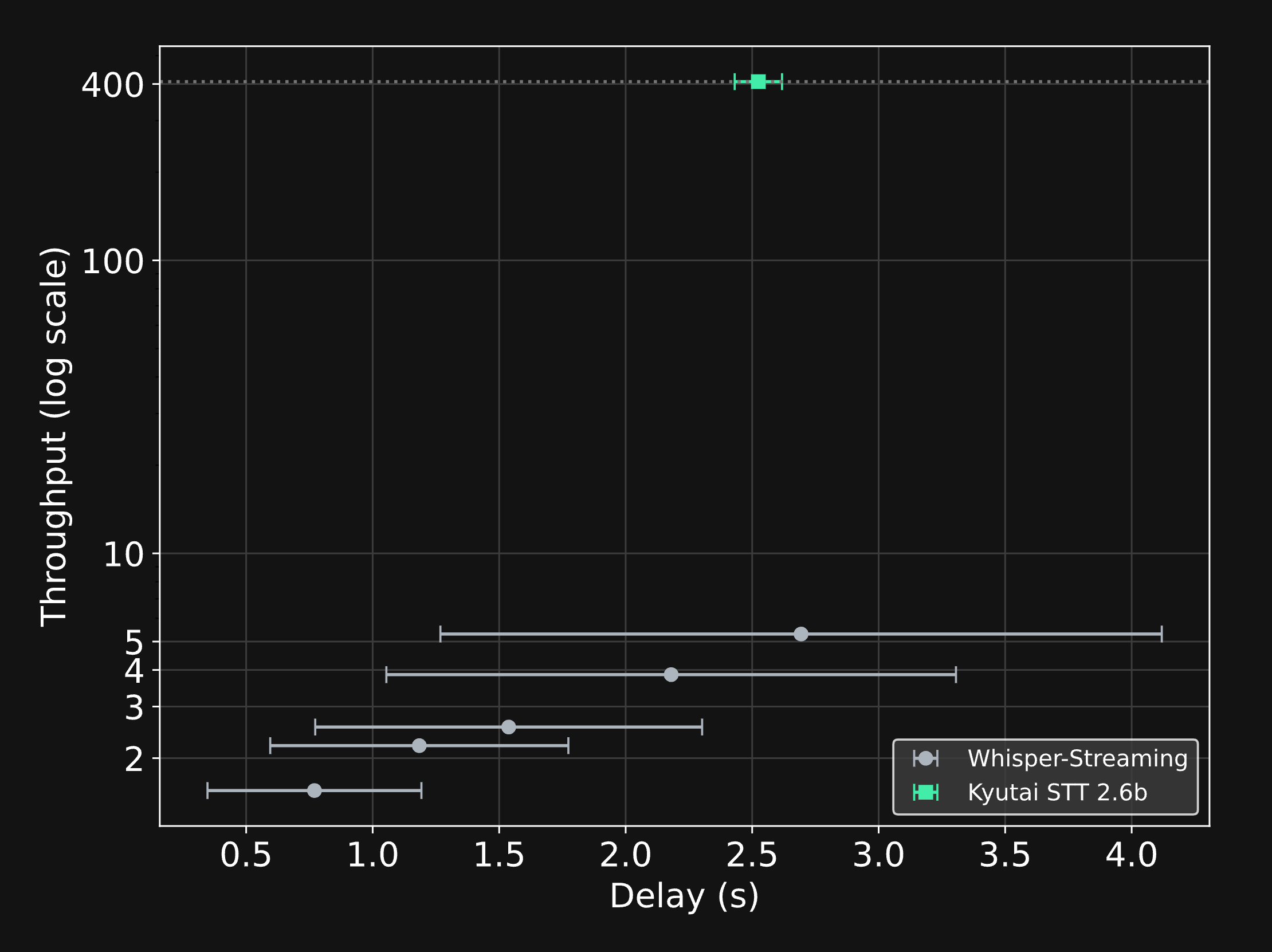
Efficient real-time processing is where Kyutai STT shines. It can transcribe 400 audio streams at once in real time on a single H100.
Here we only benchmarked the 2.6B model; the throughput of the 1B is even higher!
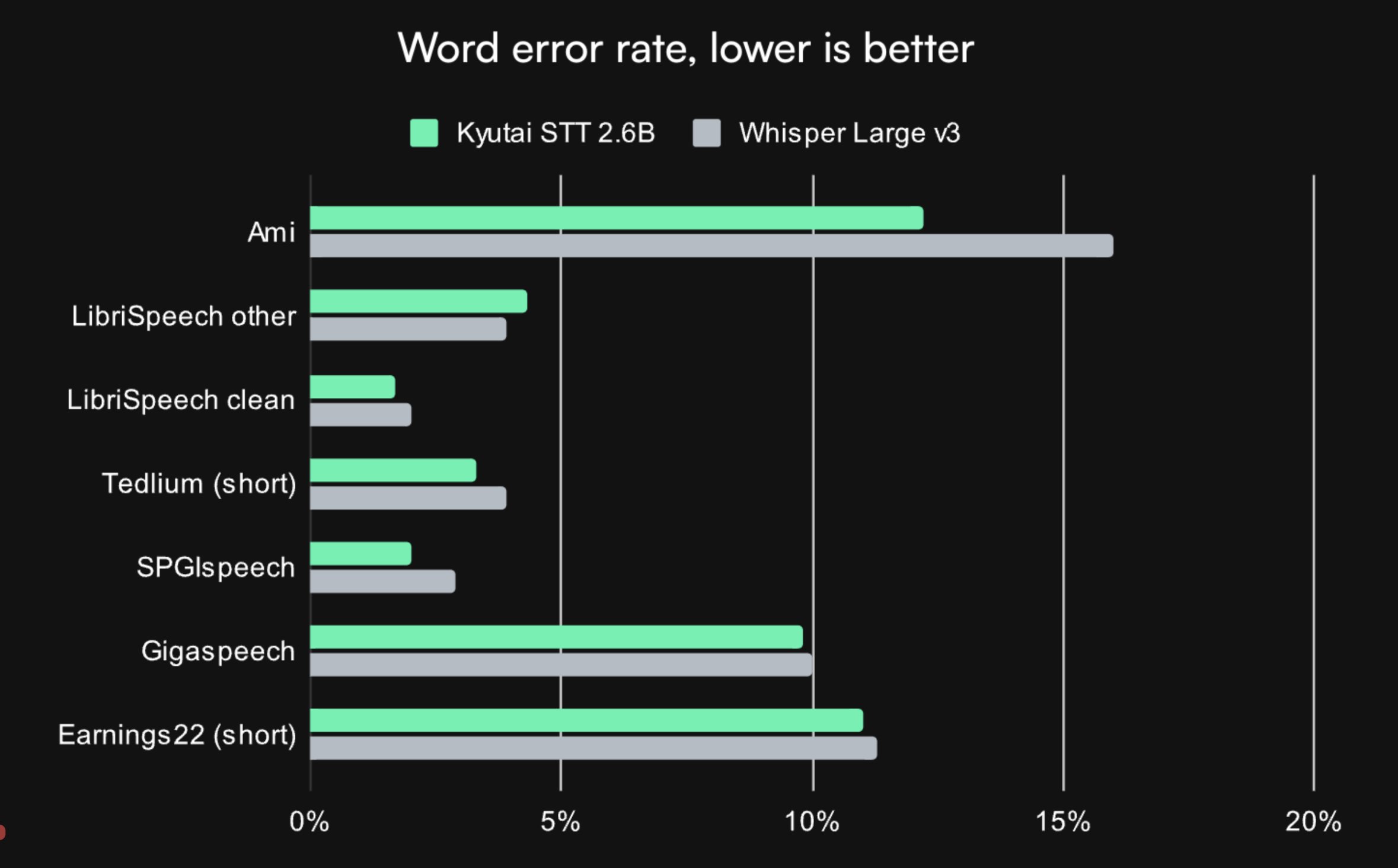
Our 2.6B model performs on par with state-of-the-art non-streaming models that have access to the whole audio at once.
Text-to-speech and Unmute are around the corner
We’re working hard on releasing the rest of the Unmute project, that is, Kyutai TTS and the Unmute codebase itself. We aim to have both out within a week or two.
For the text-to-speech, we could use your help. We’re collecting voices to release along with the TTS to provide a starting set of voices to choose from. You can contribute by sending us an anonymous recording of your voice.
We’re excited to see what you can create with our growing collection of open-source models. Don’t hesitate to open an issue on GitHub if something doesn’t work for you.