CASA
Cross-Attention over Self-Attention
Moritz Böhle*, Amélie Royer*, Juliette Marrie*, Edouard Grave, and Patrick Pérez.
We revisit cross-attention (CA) as a fusion mechanism for vision-language models (VLMs), a design that has been largely put aside in favor of token insertion in recent year, despite CA’s favorable efficiency properties for streaming understanding tasks.
While several early multimodal models relied on cross-attention, current SotA VLMs instead use direct token insertion, where image embeddings produced by a vision encoder are directly interleaved with text tokens in the language model stream. This allows full interaction between modalities, but it also causes memory and compute costs to grow with the number of images processed, as image tokens accumulate in the model’s KV-cache.
In contrast, cross-attention injects visual information through additional dedicated CA layers, where text tokens (queries) attend to image tokens (keys and values). By design, when extending cross-attention to a text-image interleaved sequence containing multiple images, we only use the latest seen image as key-value of the cross-attention layers. At inference time, the model has direct access only to the most recently observed image. To align training with this behavior, we implement cross-attention in local attention windows delimited by image occurrences, e.g., between two video frames. In addition, image tokens are not updated throughout the network, as opposed to token insertion, and are not added to the LLM’s KV-cache, which brings practictal advantages in terms of compute and memory cost.
In our preprint, we analyze the differences between cross-attention and token insertion, and show that when trained in comparable settings (e.g., the same data distribution), the performance gap between the two approaches is much smaller than anticipated, and our resulting CA models outperform prior cross-attention–based VLMs. Our evaluation spans several standard vision-language benchmarks covering tasks such as visual question answering, document understanding, OCR, and video understanding. To further highlight the benefits of CA for streaming applications, we also finetune our model for live video captioning, where CA enables almost constant memory cost and inference cost over video streams.
Example of live video captions generated with our CASA-Qwen2_5-VL-3B-LiveCC model on two videos from the Animal Kingdom dataset. Code to reproduce such examples is available in our github repository
. Additional samples are available at at the bottom of this page.
Takeaways
- CA is a competitive alternative to token insertion. When trained under comparable conditions (e.g., the same data distribution), CA-based VLMs achieve performance close to token insertion models on most benchmarks, with a remaining gap on some high-resolution tasks such as InfographicVQA.
- CA efficiently injects visual information into LLMs. In standard CA models, image tokens are not updated through the language model’s feedforward networks, do not attend to other image or text tokens, and are not maintained in the model’s KV-cache. As a result, CA offering favorable compute and memory scaling compared to token insertion.
- CA can be flexibly integrated into existing models. It can be used either (i) to train a vision-language model from scratch starting from a text-only LLM, or (ii) to adapt an existing insertion-based VLM into a more efficient CA-based model.
- CA supports low-latency streaming applications. Because image tokens do not accumulate in the KV-cache, memory usage and inference cost remain nearly constant as more images are processed. This makes CA particularly well suited for streaming applications such as live video captioning.
Table of Contents
- Motivation
- Model Training and Release
- Quantitative Evaluation
- Efficiency Analysis on Live Video Captioning
- Qualitative Samples
Motivation
Early multimodal transformers relied on cross-attention (CA) to fuse visual and language information by injecting image features into a language model through dedicated attention layers. More recently, however, most vision–language models have adopted token insertion, where image tokens are directly interleaved with text tokens in the language model stream, and are updated alongside the text token e.g. through the FFN layers. Empirically, token insertion models has often been reported to largely outperform cross-attention models. This raises a natural question: Is this gap intrinsic to the fusion mechanism, or does it arise from differences in training setups and architectural choices?
To answer this question, we analyze the structural differences between cross-attention and token insertion, to progressively bridge the gap between the two designs. Our experiments show that, when trained under identical conditions at the 2B–3B scale, the performance gap between the two fusion mechanisms is substantially smaller than suggested by prior comparisons. Nevertheless, a gap remains on specific tasks such as document and infographic understanding, showing the additional cost of token insertion is justified in some applications.
To Cross-Attend or to Self-Attend?
Cross-attention and token insertion differ in several key respects.
In our preprint, we analyze these differences and their practical impact in detail. Below, we briefly highlight three of the main ones.
Additional parameters
Cross-attention introduces new learnable parameters by adding separate attention projections. To remove this overhead, we also provide a shared-projection variant, denoted CA🔗, where cross-attention and self-attention reuse the same parameters.
Image token updates
In cross-attention models, the same image tokens are reused to update text tokens at every cross-attention layer. Token insertion, by contrast, updates image tokens throughout the network through both self-attention and feed-forward layers. This usually improves performance, but comes with a substantial memory and compute overhead.
Visual history
Cross-attention does not retain past image tokens in the KV-cache. As a result, the model only has direct access to the latest image, whereas token insertion retains the full visual history. This is key for the scalability of cross-attention models to long input contexts, but may be detrimental to performance when the task requires knowledge of the past visual context.
Despite the lack of direct access to past images, we also note that visual information can still be propagated through tokens present in the text stream: In particular, image delimiter tokens, which are common in many VLM chat templates can act as "gist tokens", compressed carriers of visual context, which have been explored in past works on context compression for text and image models.
The table below summarizes these trade-offs:
| Model | Properties | Training | Streaming inference | ||||
|---|---|---|---|---|---|---|---|
| New params | Update image tokens | Text toks/s | Mem. | FPS | Mem. | #KV | |
| CA | Yes | No | 1817 | 32.9 | 6.8 | 6.1 | kT + N |
| CA🔗 | No | No | 1845 | 32.0 | 7.7 | 5.7 | kT + N |
| CA w/ image FFNs | Yes | Yes | 1504 | 57.8 | 6.6 | 6.1 | kT + N |
| Token insertion | No | Yes | 1501 | 62.8 | 1.2 | 29.5 | kT + kN |
CA with Local Attention Windows

To preserve efficiency in streaming settings, our CA layers use local attention windows.
These windows are naturally delimited by image occurrences: Each window contains a single image (or several consecutive images) together with the text tokens associated with that visual input. In practice, this attention pattern can be implemented efficiently using block-wise attention with FlashAttention, which also enables efficient training with sequence packing.
In the streaming video captioning setting, these local attention windows restrict CA layers to a single frame (sampled at 2 fps) and the caption tokens associated with that timestamp, which typically amount to only a few tokens. This windowed design effectively behaves like an aggressive KV-cache eviction strategy, where only the most recent image is kept in memory. The global textual coherence of the generated caption stream is preserved through the text-only self-attention layers of the language model, which propagate contextual information across the sequence.
Model Training and Release
To showcase CA’s applicability for both extending language-only models with visual understanding as well as adapting existing VLMs, we train our models in two settings:
- Starting from Helium1-2B, a text-only LLM, which we fully fine-tune alongside additional CA layers to obtain a CA-based Helium1 model.
- Adapting Qwen2.5-VL-3B, a pretrained VLM that originally inserts image tokens directly into the input stream. In this setting, we keep the backbone VLM frozen and adapt it to CA by training only the additional CA layers.
In both cases, images are embedded using the visual encoder of Qwen2.5-VL before being fed into the CA layers, and we fine-tune its last four blocks.
Vision-Language Models
All models are first trained on a combination of publically available datasets: Namely, the FineVision dataset, and a subset of LLaVA-OneVision-1.5, which together cover a wide range of tasks including image captioning, document and chart understanding, and general visual question answering.
🔹 CA-based model release
We releasekyutai/CASA-Helium1-VL-2Bandkyutai/CASA-Qwen2_5-VL-3B, pretrained on FineVision and a subset of LLaVA-OneVision-1.5.
🔹 Token insertion Helium1 release
In addition to CA-based models, we releasekyutai/Helium1-VL-2B, a VLM trained from Helium1-2B with direct token insertion on the same training dataset.Helium1-VL-2Bachieves state-of-the-art performance among insertion-based models of comparable size trained with publicly available datasets.
Live Video Captioning Models
For live video captioning, we further fine-tune our CASA-Qwen2_5-VL-3B models on the Live-WhisperX-526K dataset, which is an instruction-style video dataset for live captioning, consisting of video frames sampled at 2 fps and interleaved with the corresponding text transcripts of the original video audio.
🔹 LiveCC CA-based models.
We releaseCASA-Qwen2_5-VL-3B-LiveCC, further finetuned on Live-WhisperX for live streaming.
Quantitative Results
We evaluate our image-based models CASA-Helium1-VL-2B, Helium1-VL-2B and CASA-Qwen2_5-VL-3B
on a range of benchmarks covering document understanding (DocVQA), chart understanding (ChartQA, InfoVQA),
visual text reading (TextVQA, OCRBench), and general QA (RealWorldQA, AI2D, GQA, MME).
| Model | Document / Chart | Scene Text | Knowledge / QA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ChartQA | DocVQA | InfoVQA | OCRBench | TextVQA | RealWorldQA | AI2D | GQA | MME | |
| Insertion (He-2B) | 81.6 | 89.1 | 61.8 | 728 | 75.5 | 59.9 | 67.7 | 55.5 | 1732 |
| CASA (He-2B) | 73.4 | 83.7 | 48.6 | 723 | 71.0 | 58.3 | 63.3 | 54.6 | 1572 |
| mPLUG-Owl3 8B | 59.2† | 55.9† | 36.8† | 527† | 69.0 | 63.9† | 73.4 | 65.0 | 1940† |
| mPLUG-Owl3 2B | 48.5† | 48.2† | 28.1† | 450† | 62.6 | 56.9† | 62.6 | 61.0 | 1551† |
† Reproduced with the publicly available models on HuggingFace.
Comparing different vision-language fusion mechanisms in the 2-3B range.
We compare our models trained from scratch from the text-only Helium1-2B (CASA-Helium1-VL-2B, orange),
a recent cross-attention (CA) baseline (in blue),
and our token insertion baseline trained from Helium1 (Helium1-VL-2B, gray).
Evaluation is performed using the lmms-eval pipeline and we
provide code to reproduce our results in our repository.
| Model | Document / Chart | Scene Text | Knowledge / QA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ChartQA | DocVQA | InfoVQA | OCRBench | TextVQA | RealWorldQA | AI2D | GQA | MME | |
| Qwen2.5-VL 3B | 84.0 | 93.6 | 77.1 | 797 | 79.3 | 62.2† | 81.6 | 61.0† | 2249† |
| CASA (Qwen2.5-VL 3B) | 82.4 | 88.9 | 59.6 | 790 | 77.4 | 62.5 | 75.1 | 59.4 | 1918 |
† Reproduced with the publicly available models on Hugging Face.
Adapting a frozen pretrained Qwen2.5-VL.
Our CASA-Qwen2_5-VL-3B model reaches performance close to the original insertion-based model
while keeping the base model frozen and training only the CA layers.
Efficiency Analysis on Live Video Captioning
We further finetune our Qwen2.5-VL CA-based model on the Live-WhisperX dataset introduced in LiveCC (Chen et al, 2025). In contrast to token insertion, CA does not introduce any memory overhead as image tokens are not stored in the KV-cache but simply replaced as inputs to the CA layers' K and V projections for every new video frame. As a result, CA can be applied on long videos with a significantly reduced memory bottleneck.
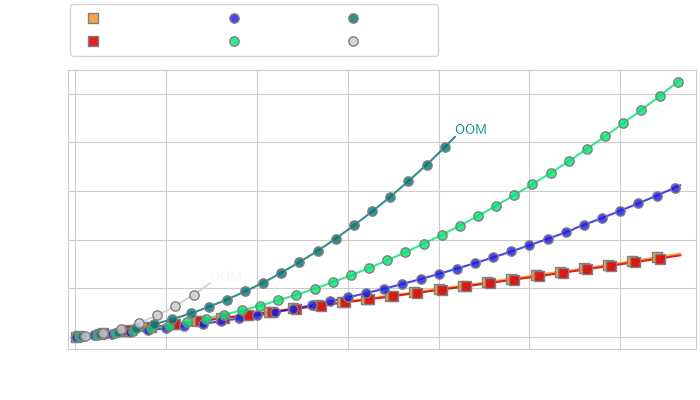
Wall-clock time vs number of turns
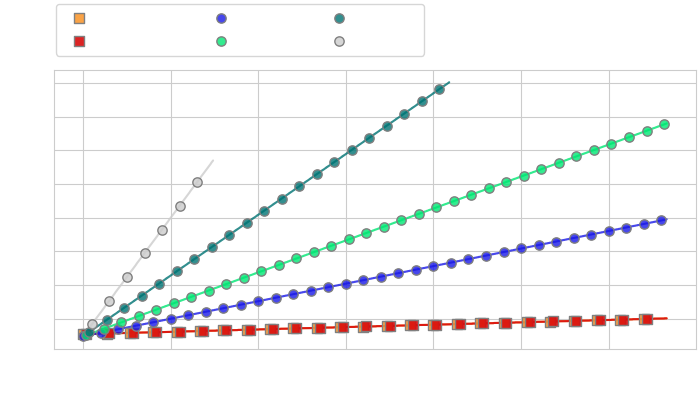
Memory vs number of turns
Efficiency Analysis of CA vs token compression for streaming applications. We compare the computational cost (left) and memory cost (right) of CA and token compression methods (Q-Former with varying numbers of query tokens) on the task of live video captioning for video frames extracted at 2fps, with roughly 5 text tokens generated between each consecutive frame.
While token compression reduces the cost of token insertion for short conversations, it cannot alone prevent the increased memory usage leading to OOM when the number of tokens is too high (left). In contrast, CA maintains high inference speed over much longer horizons (right), while always making high-resolution image information available to the model.
Additional Qualitative Samples
Additional samples are available as a gallery in the following HuggingFace space, embedded below (best seen in Chromium-based browsers).